Pipelining
Split a calculation into registered stages to increase FPGA circuit throughput.
Core Idea
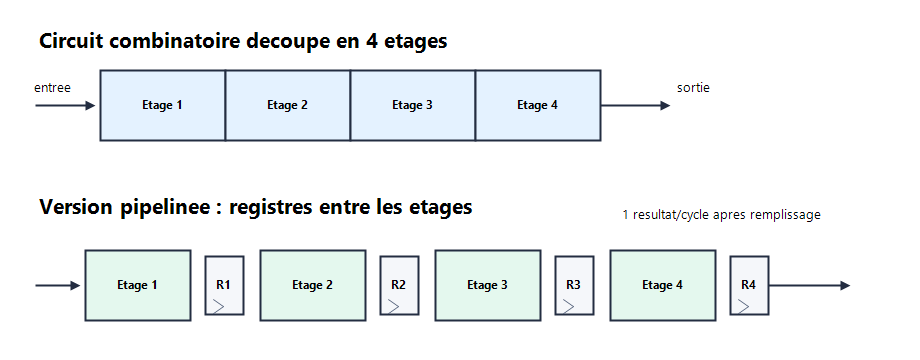
Pipelining means splitting a long combinational path into several stages, then placing registers between those stages.
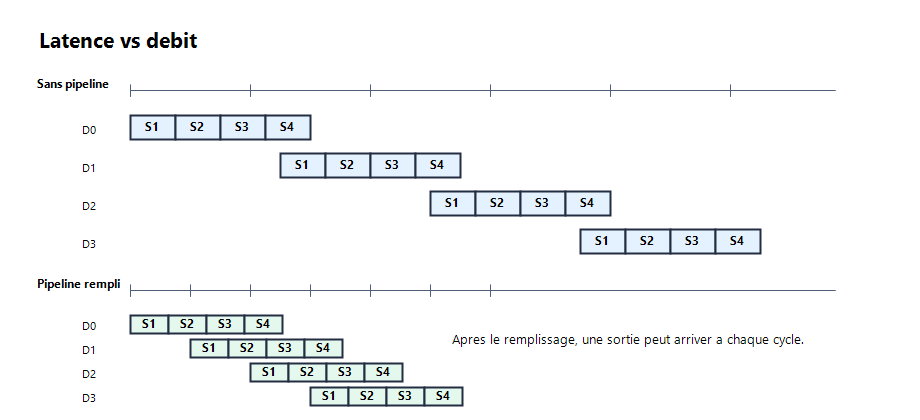
Without a pipeline, one data item crosses the full logic path before it is captured. With a pipeline, several data items move at the same time, each one in a different stage. The first result is not produced sooner, but results can be produced more often once the pipeline is full.
Latency and Throughput
Two notions must be separated:
| Notion | Meaning |
|---|---|
| Latency | Time between one input and its output |
| Throughput | Number of results produced per unit of time |
Adding a pipeline usually increases cycle latency. However, the critical path in each cycle becomes shorter, so the maximum clock frequency can increase.
Example with 4 stages:
- without a pipeline: one data item must cross all 4 calculations before output;
- with a pipeline: after filling, 1 result can be produced every cycle;
- the first data item appears after several cycles, then the following outputs are paced.
Critical Path
The clock period must cover the slowest stage:
Tclk >= Tmax_stage + Tsetup + TcqTsetup and Tcq are register costs. A very deep pipeline is therefore not always better: if stages become too small, register overhead dominates.
A good pipeline mainly tries to balance the stages. If one stage takes 40 ns and the others take 15 ns, frequency is still limited by the 40 ns stage. The logic must be moved or reorganized to get stages with similar delays.
VHDL Example
Non-pipelined calculation:
o_y <= std_logic_vector(unsigned(i_a) * unsigned(i_b) + unsigned(i_c));Two-cycle pipelined calculation:
P_PIPE : process(i_clk)
begin
if rising_edge(i_clk) then
if i_rst = '1' then
r_mul <= (others => '0');
o_y <= (others => '0');
else
r_mul <= unsigned(i_a) * unsigned(i_b);
o_y <= std_logic_vector(r_mul + unsigned(i_c));
end if;
end if;
end process P_PIPE;Register r_mul cuts the critical path between multiplication and addition. The output corresponds to inputs from a previous cycle, so the testbench must always check the latency.
Key Points
- Pipelining increases throughput, not necessarily single-item latency.
- Each register adds timing and area overhead.
- Signals that belong to the same data item must move together through registers.
- A testbench must verify the temporal offset between input and output.
📝 Test your knowledge - Chapter quiz